Imitation Learning using Denoising Diffusion Models
10 715: Deep Reinforcement Learning and Control, Prof. Katerina Fragkiadaki
Diffusion Policy
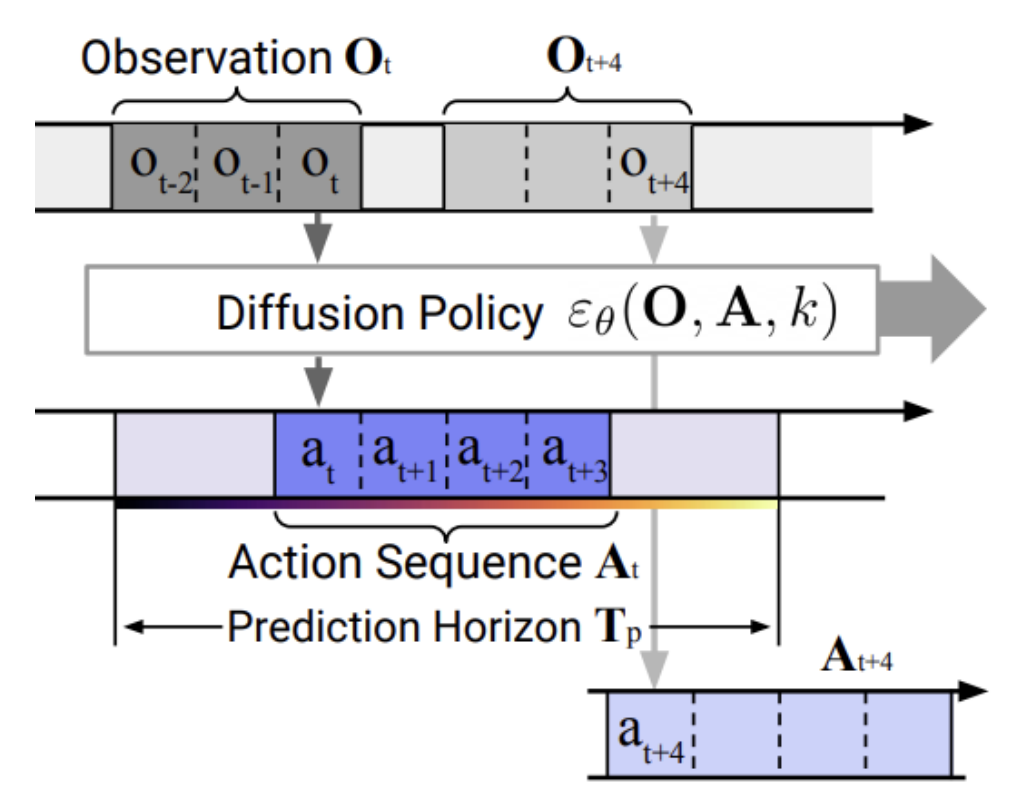
Implemented Imitation Learning using diffusion policies for the BipedalWalker-v3 environment in Gymnasium. Designed a transformer-based policy architecture takes as input a history of states, actions, and episode timesteps and predicts future actions through denoising diffusion process. The expert trajectories to imitated were supplied by the Proximal Policy Optimization (PPO) algorithm as a substitute for human demonstrations.

DAgger & Behavior Cloning

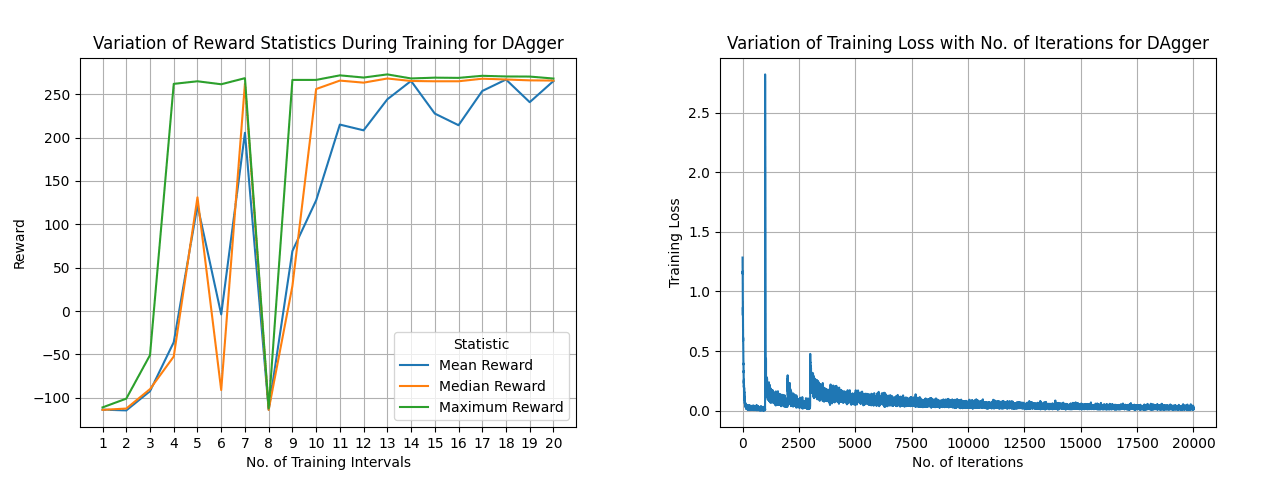
Implemented DAgger by training a policy through supervised regression to map observations to actions using a dataset of expert trajectories (state-action pairs). Designed a residual three-layer multilayer perceptron (MLP) as the policy network, outputting actions within the range [-1, 1]. The training loss plot, along with the average, median, and maximum reward for each batch collection step during trajectory collection using the DAgger algorithm, is shown above.
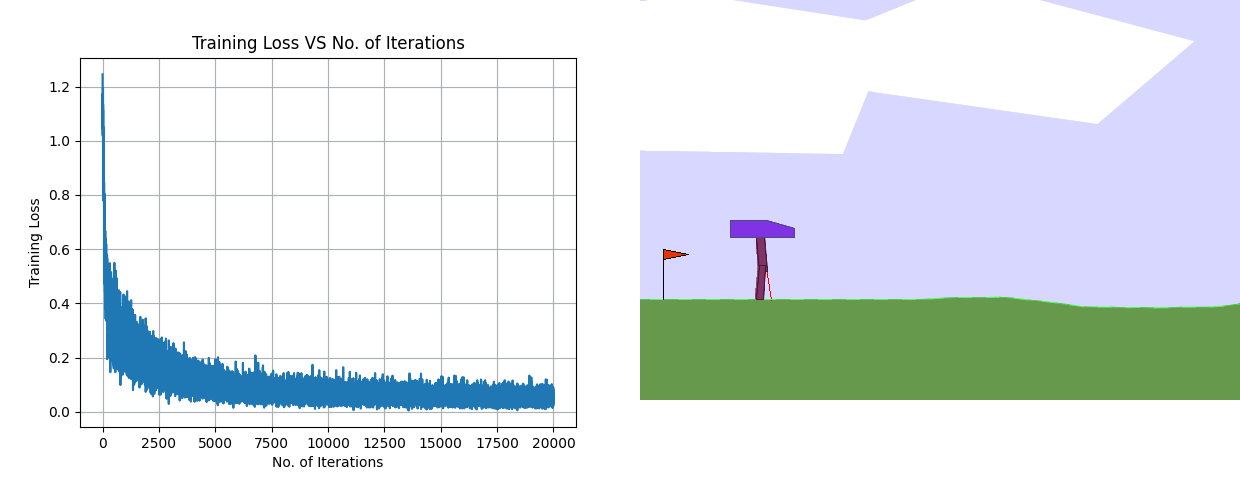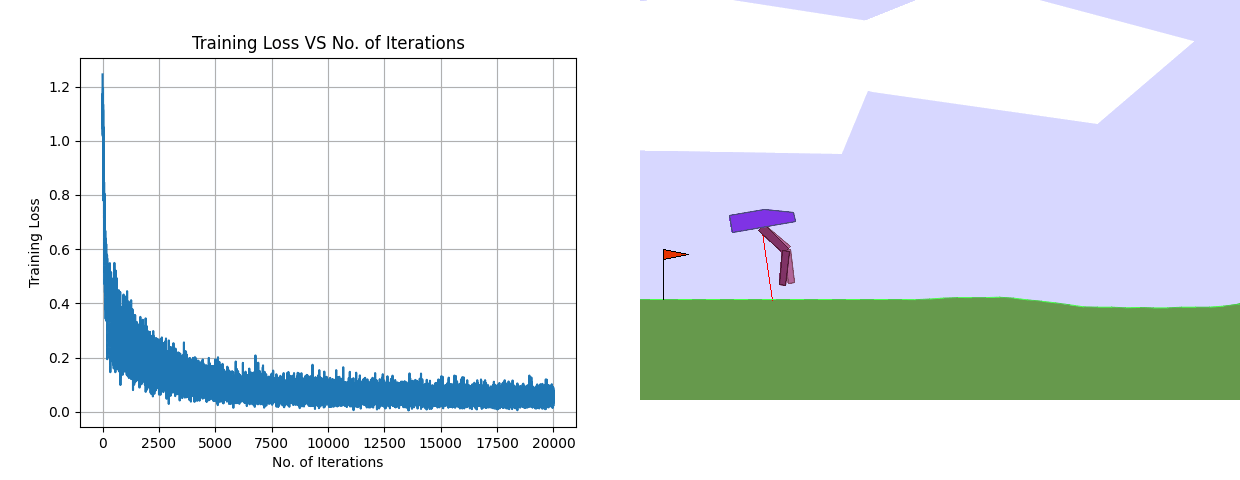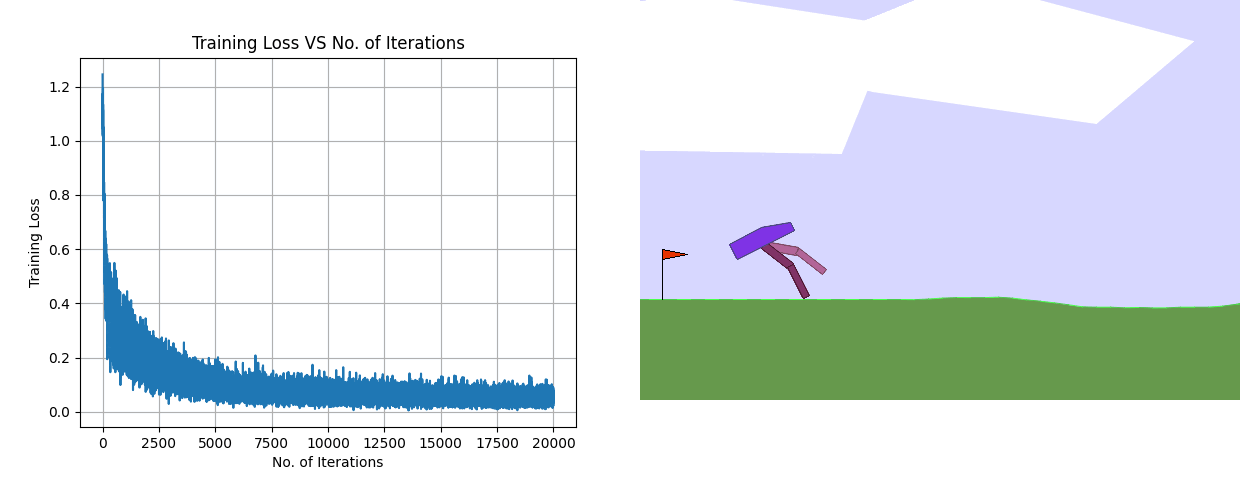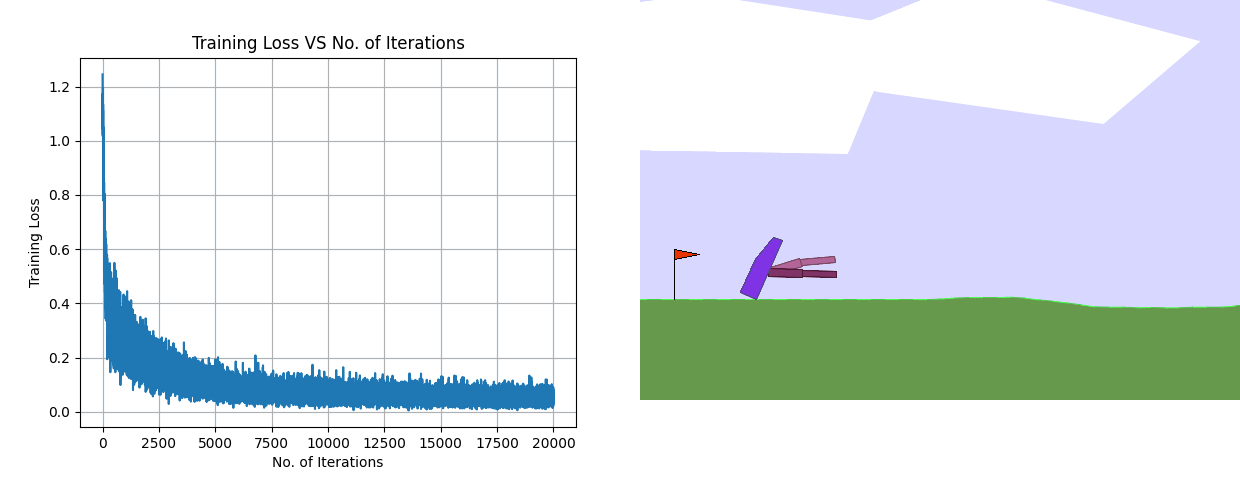
Using the same architecture, the training loss plot along with the results of the final deployed policy for Behavior Cloning is shown above. Despite having a considerably low training loss, the BC policy fails miserably.