MuZero VS Model-Free RL
10 715: Deep Reinforcement Learning and Control, Prof. Katerina Fragkiadaki
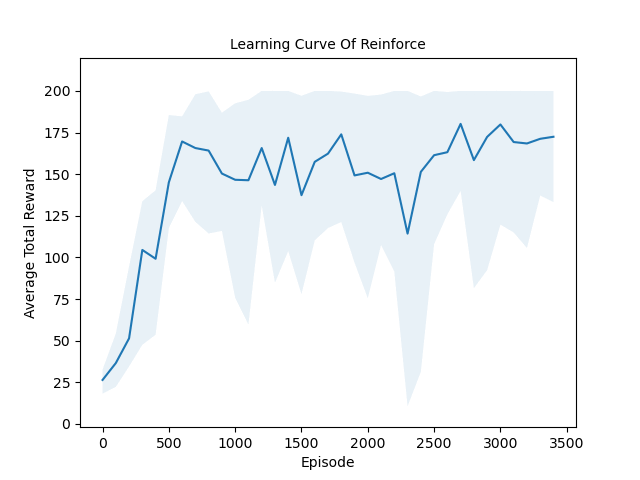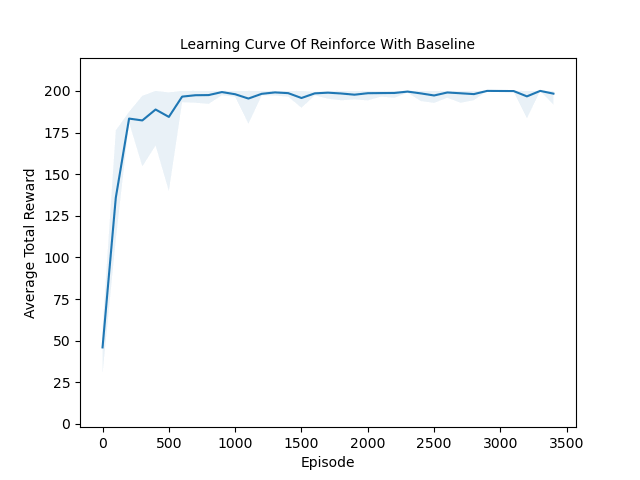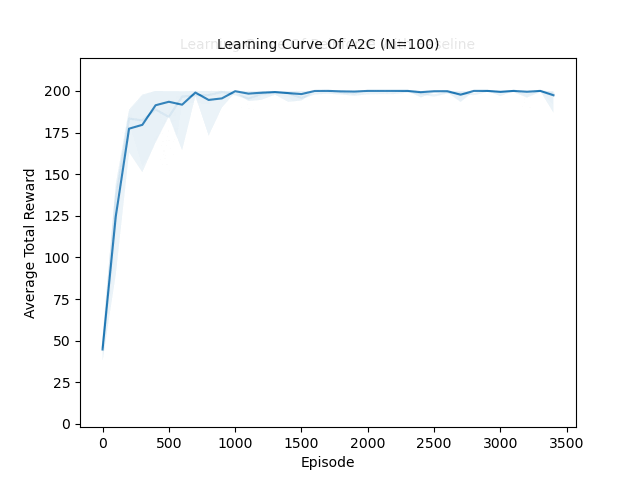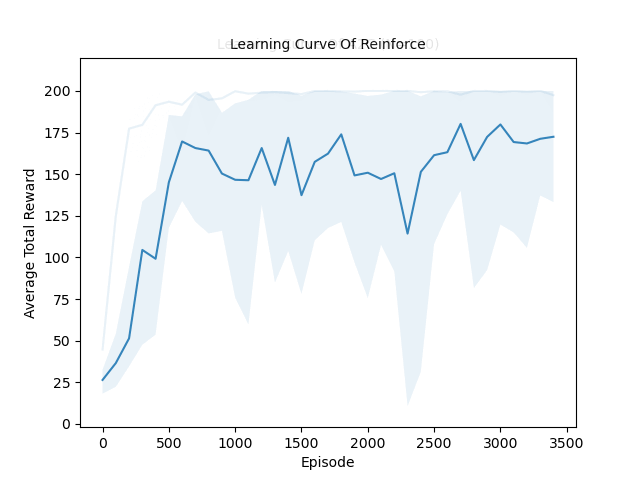
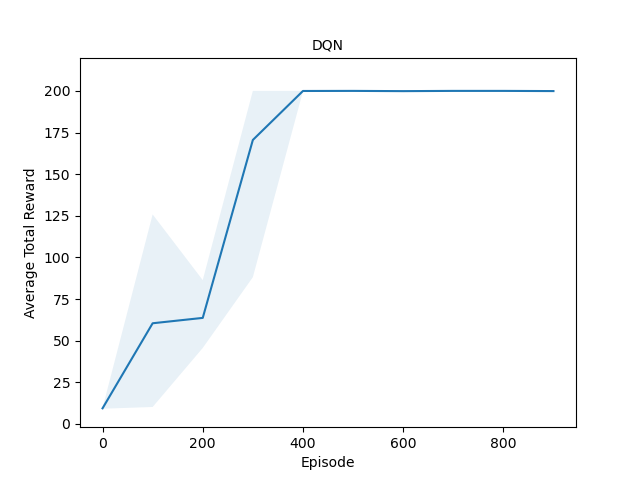
Evaluated the performance of model-free RL algorithms (Actor-Critic, DQN, REINFORCE) against the model-based MuZero algorithm on the CartPole-v1 environment in Gymnasium.
MuZero
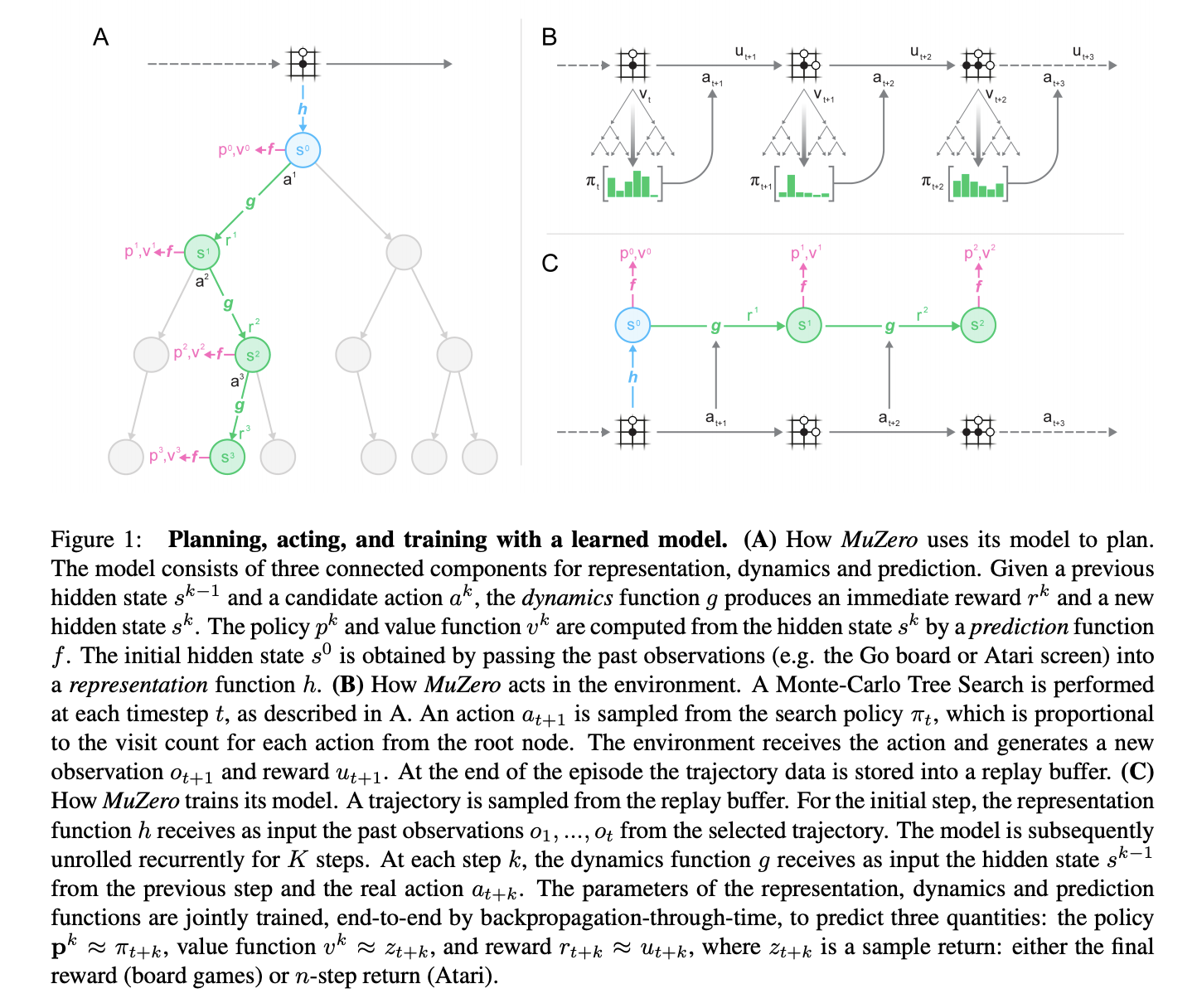
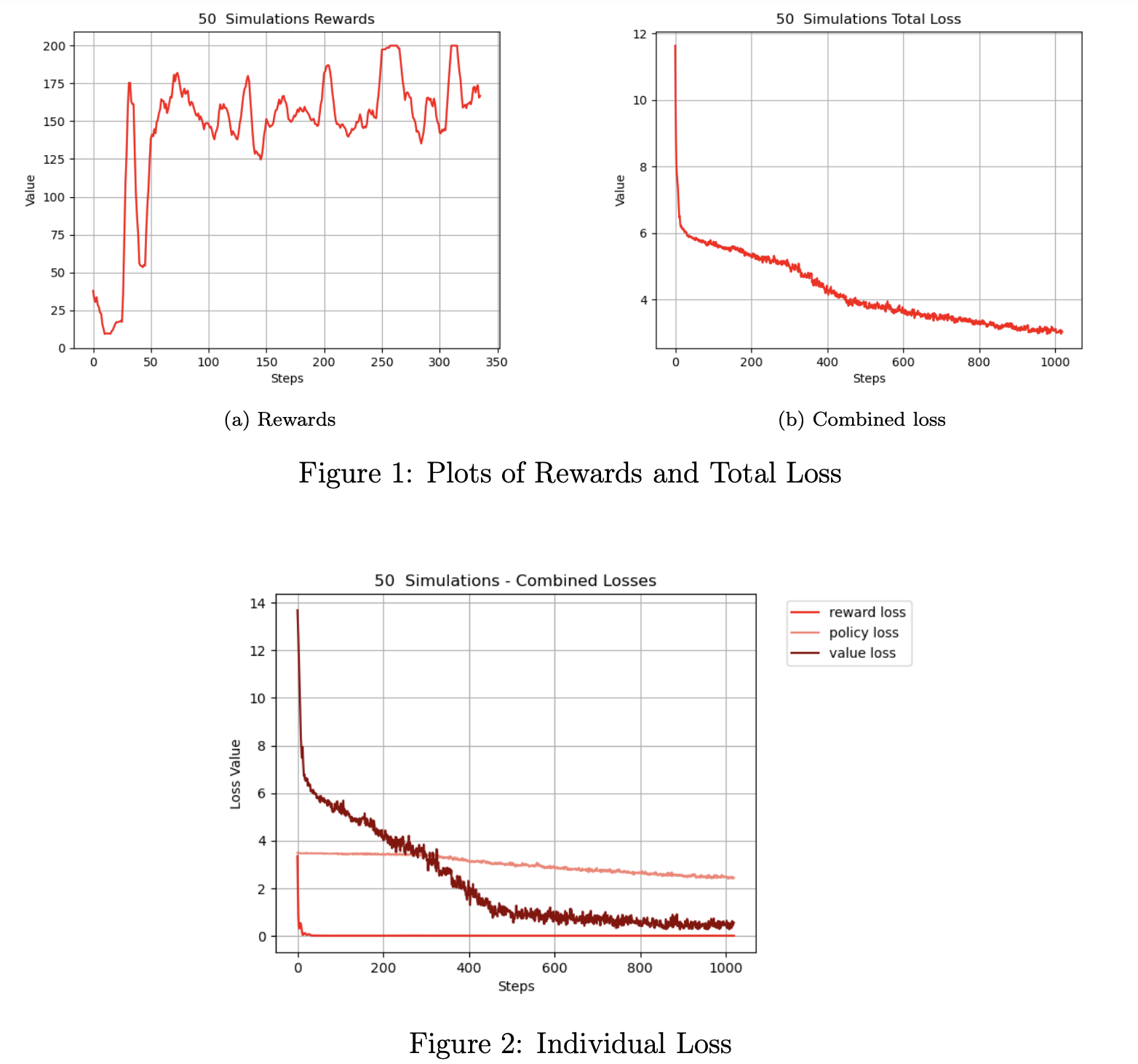
Implemented a non-parallelized version of the MuZero algorithm to solve the OpenAI Gym CartPole-v1 environment. Developed key components of the Monte Carlo Tree Search (MCTS), including child selection, node expansion, backpropagation, and action sampling. Designed neural network architectures for state representation, dynamics prediction, value estimation, policy prediction, and reward prediction. Created a training loop for the MuZero agent with loss functions for value, policy, and reward predictions, achieving convergence within 30 training epochs. Conducted hyperparameter tuning experiments to optimize MCTS simulations and analyzed their impact on performance, while visualizing training metrics such as test rewards and loss components.
Model-Free Algorithms: A2C & DQN