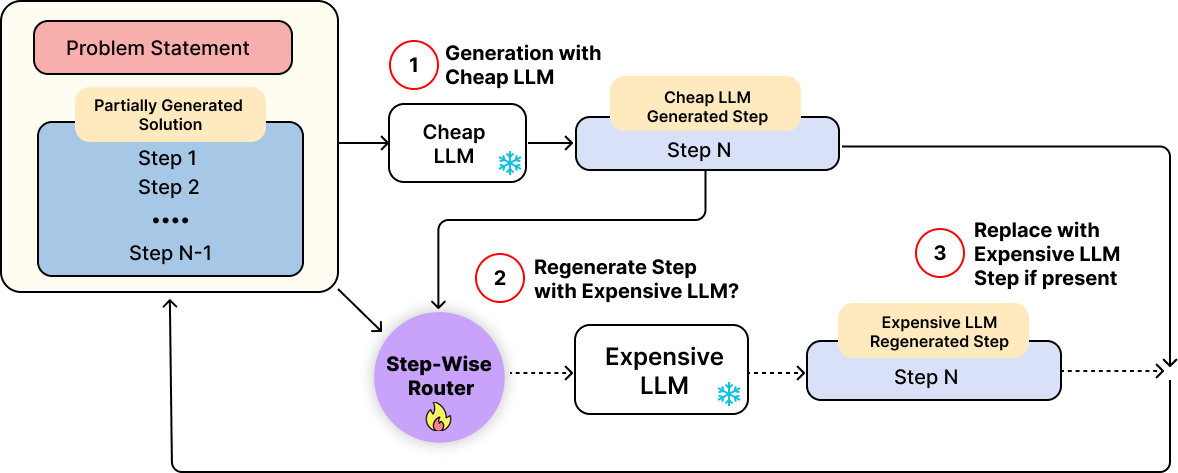
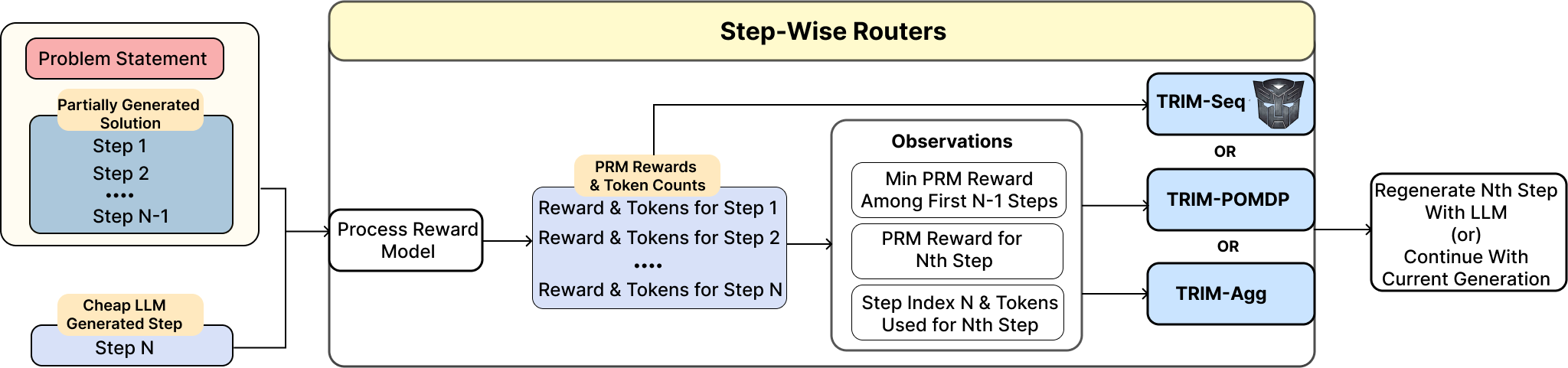
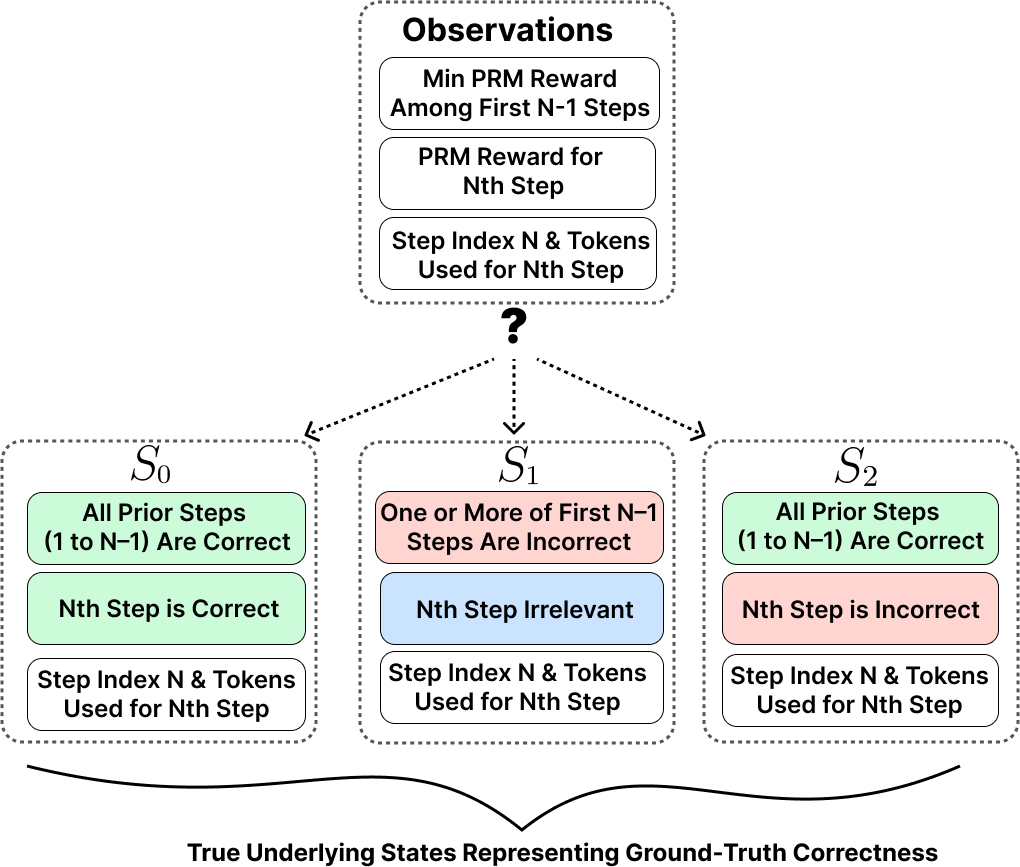
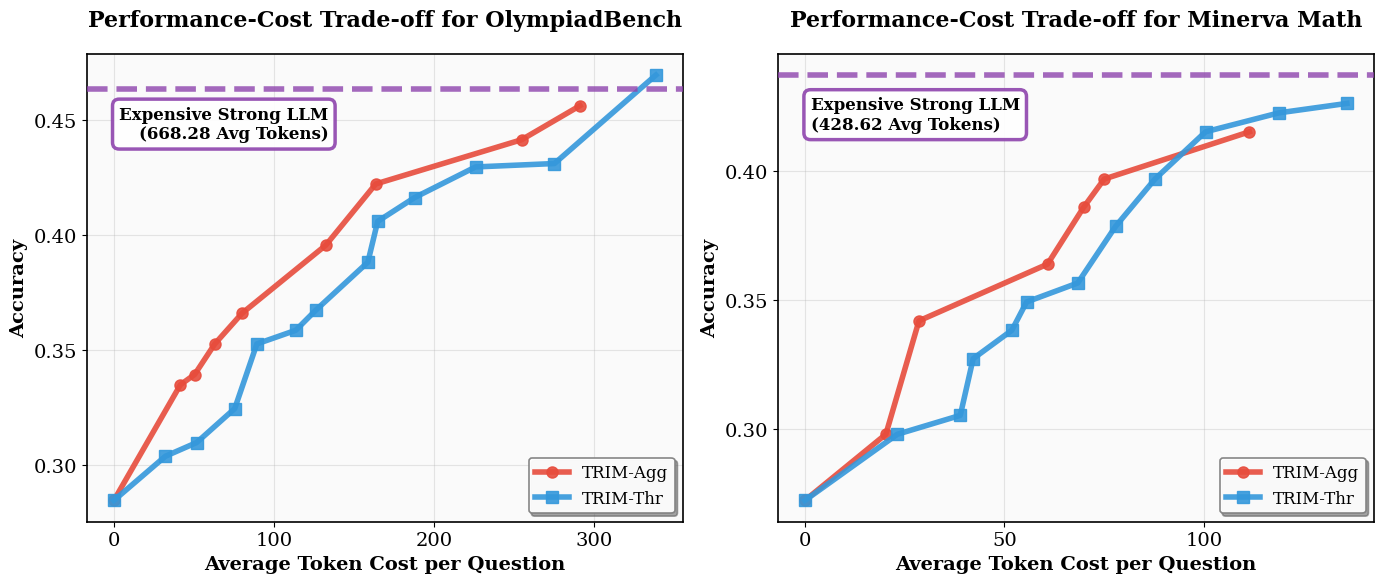
From Simple Thresholding to Trajectory-Aware Routing
We instantiate TRIM with routing policies of increasing sophistication. The simplest policy, TRIM-Thr, uses only the PRM score of the current step, while the more expressive policies incorporate trajectory-level information to reason about whether intervention is still likely to improve the final solution enough to justify its cost.
TRIM-Thr: A Simple and Effective Myopic Policy
We first introduce TRIM-Thr, a simple routing policy that relies solely on the PRM score of the current step generated by the weak model Mw. If this score falls below a predefined threshold k, the router regenerates the step with the strong model Ms; otherwise, it accepts the weak model’s output and continues generation.
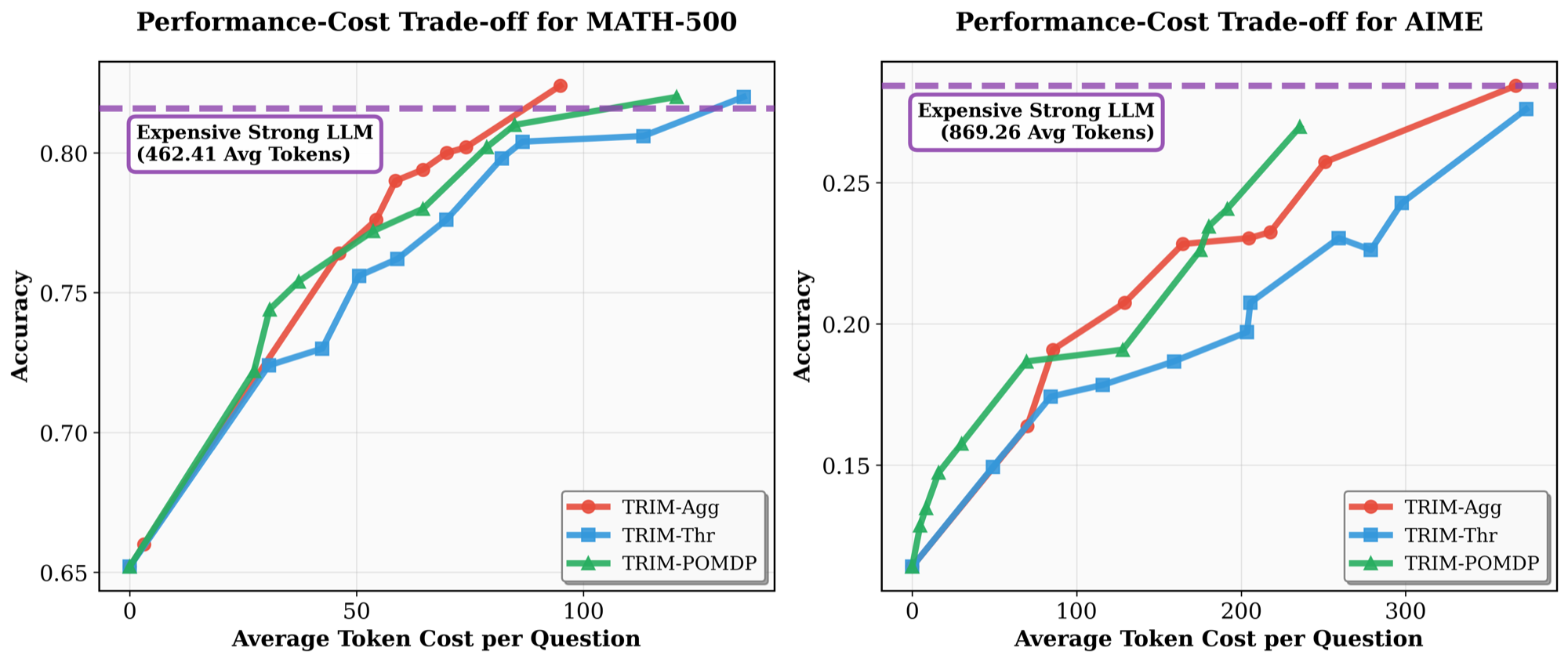
Despite its simplicity, TRIM-Thr is highly effective. The threshold parameter k provides a principled mechanism for controlling the performance-cost trade-off: lower thresholds reduce strong-model usage, while higher thresholds allow more aggressive intervention. Empirically, this simple step-level policy already outperforms prior query-level routing methods and is competitive with an idealized oracle query-level router that selects the best model per query.
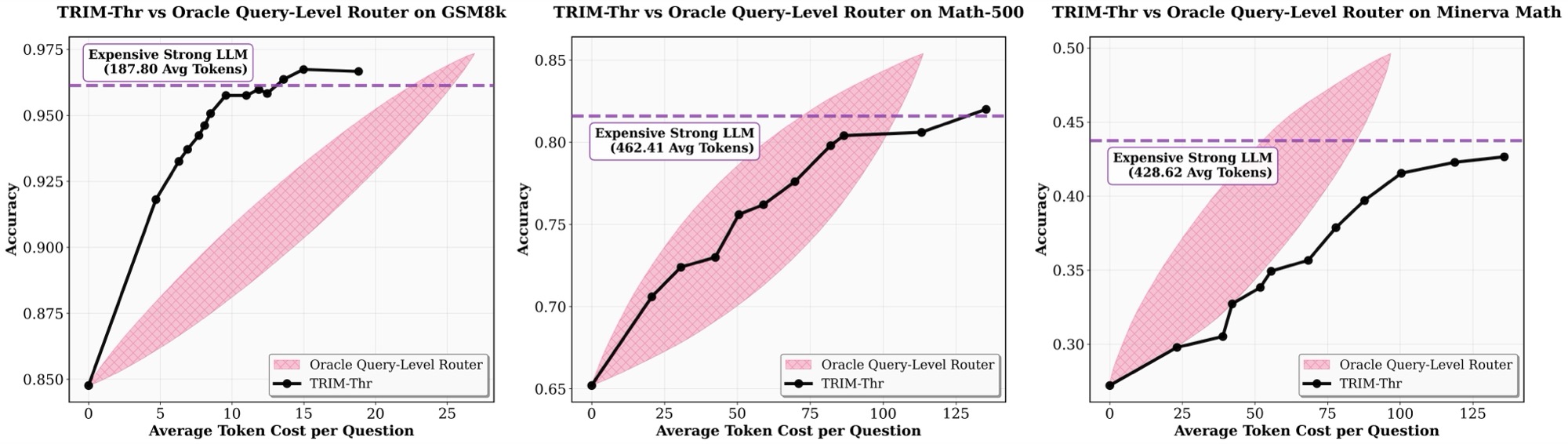
TRIM-Thr VS Idealized Oracle Query-level Router. Comparison of task performance–cost trade-offs for Qwen2.5-3B-Instruct (Mw) and Claude 3.7 Sonnet (Ms), under
the TRIM-Thr (with Qwen2.5-Math-PRM-7B) versus the Idealized Oracle Query-level Router.
Why Go Beyond Thresholding?
While TRIM-Thr performs remarkably well, it is inherently myopic: it makes routing decisions using only the correctness estimate of the most recent step, without accounting for past context or future consequences. In many cases, the current step alone is insufficient for deciding whether intervention is worthwhile.
For example, even if the current step appears incorrect, regeneration may not be beneficial if the overall trajectory has already diverged too far from a correct solution, or if the cost of invoking Ms outweighs the potential gain. Conversely, when earlier steps remain largely consistent, a targeted intervention can recover the trajectory and substantially improve final correctness.
This motivates richer routing policies that reason jointly about trajectory correctness and marginal intervention cost.
TRIM-Seq: Learning from Sequential Features
TRIM-Seq learns routing decisions from the full sequence of step-level signals accumulated along the reasoning trace. At each step, the router observes the sequence of correctness estimates and token counts from prior steps, allowing it to reason over how the trajectory has evolved rather than focusing only on the latest PRM score.
Concretely, TRIM-Seq uses the feature sequence
(r1, c1), ..., (rt, ct),
where ri denotes the PRM score of step i and ci denotes its token length. These features capture the two quantities most fundamental to routing in multi-step reasoning: semantic fidelity, via step-level correctness estimates, and marginal intervention cost, via token counts that quantify the expense of regeneration with the strong model.
We parameterize the routing policy with a transformer over this feature sequence and train it using RL. The objective maximizes expected return by balancing final solution correctness against the cumulative cost of invoking the strong model. Each regeneration incurs a cost proportional to the number of strong-model tokens, weighted by a trade-off parameter λ, while the final reward reflects task correctness. This enables the router to learn when an intervention is likely to improve solution quality enough to justify its cost.
TRIM-Agg: Learning from Compact Aggregate Features
While TRIM-Seq exploits the full sequential history, much of the relevant structure can be captured using a compact set of aggregate statistics. In multi-step reasoning, errors often exhibit a compounding structure: a single incorrect step can invalidate everything that follows, while a sequence of mildly unreliable steps can gradually push the trajectory off course.
Motivated by this, TRIM-Agg uses a reduced feature representation consisting of the current PRM score, the minimum of prior scores, the token count of the current step, and the step index. These aggregated features preserve key signals about whether the trajectory remains plausibly on track and whether intervention is cost-justified, while discarding the full sequential history.
We train TRIM-Agg with the same RL objective as TRIM-Seq. Empirically, this compact representation enables substantially faster training with little to no loss in performance, making it a particularly attractive practical instantiation of TRIM framework.
Summary: TRIM-Thr offers a simple and strong stepwise routing rule, while TRIM-Seq and TRIM-Agg leverage trajectory-level correctness and cost signals to learn more principled intervention policies under explicit performance-cost trade-offs.
TRIM-POMDP: Routing Under Noisy Step-Level Signals
A final challenge in stepwise routing arises from the imperfect nature of PRM estimates. Although PRMs provide useful signals about the correctness of intermediate steps, their predictions are often noisy and can misclassify correct steps as incorrect, or vice versa. In principle, RL-trained routers can learn to compensate for this noise, but training such policies under long-horizon sparse rewards is often sample-inefficient and expensive.
TRIM-POMDP addresses this by explicitly modeling PRM scores as noisy observations of an unobserved latent state that reflects the true correctness status of the reasoning trajectory. Rather than acting directly on raw PRM outputs, the router first infers the latent state and then plans accordingly, casting routing as a partially observable Markov decision process (POMDP).
Why a POMDP?
TRIM-POMDP defines a compact latent state space with three correctness classes: S0, where the trajectory remains correct so far; S1, where the trajectory has already diverged irrecoverably; and S2, where the most recent step is incorrect but prior steps are correct, so the trajectory may still be recoverable through intervention.
POMDP formulation in TRIM. The latent state consists of three correctness classes: S0 (trajectory correct), S1 (irrecoverably incorrect), and S2 (current step incorrect but recoverable), augmented with step index and token cost. The observation space comprises PRM-based scores of prior and current steps along with auxiliary features, providing noisy signals of the underlying correctness state.
If this latent state were directly observed, routing would reduce to a standard fully observable control problem. In practice, however, the router only sees noisy PRM-based signals. This makes partial observability central to the problem rather than incidental, and motivates an explicit belief-state approach.
Modeling Noisy Step-Level Signals
To bridge the gap between noisy PRM outputs and latent correctness states, TRIM-POMDP learns an observation function that maps the history of routing observations to a probability distribution over the latent states. Concretely, this amounts to modeling the distribution of PRM-based features conditioned on each correctness class.
This observation model can be fit offline using process supervision datasets with step-level annotations, such as ProcessBench. Once learned, it can be reused across different cost budgets, since it depends only on the alignment between PRM scores and ground-truth correctness labels rather than on a specific routing objective.
By explicitly separating state inference from policy optimization (via observation function), TRIM-POMDP provides a principled way to route under noisy correctness signals without requiring expensive RL training for every performance-cost trade-off.
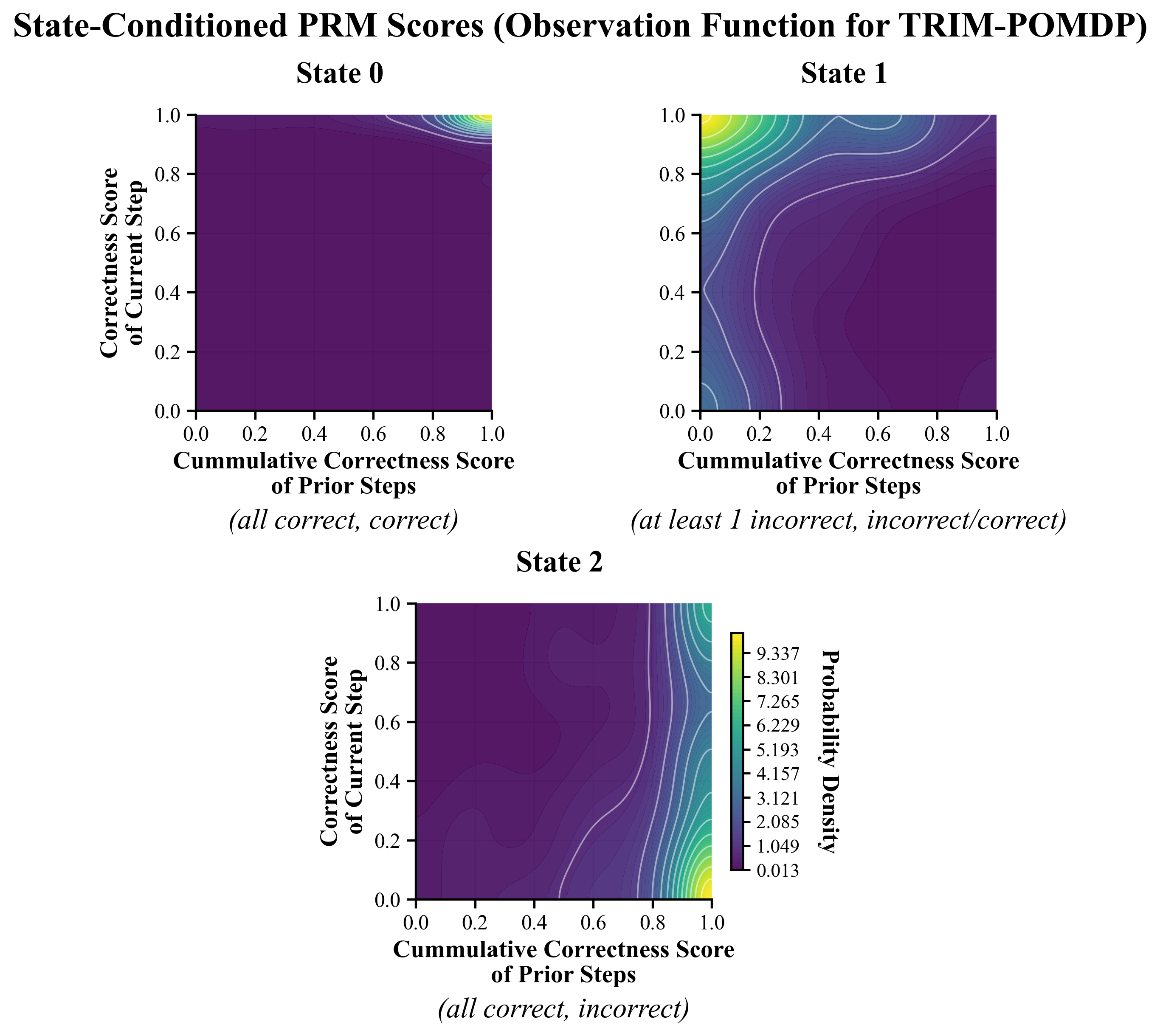
Observation modeling for TRIM-POMDP and PRM noise. Conditional PRM-score distributions reveal that step-level signals are informative but noisy, motivating explicit latent-state inference rather than direct thresholding on raw scores alone.
Once the observation model is learned, TRIM-POMDP computes routing policies using standard POMDP solvers. An additional advantage is that the resulting router is largely agnostic to the specific choice of weak and strong LLMs, depending primarily on their step-level transition characteristics. This makes the formulation modular and reusable across model pairs.
Key Takeaway: TRIM spans a spectrum from simple thresholding to learned RL policies and uncertainty-aware POMDP planning, showing that increasingly structured use of trajectory-level information leads to increasingly principled and efficient routing decisions.