Deep Recurrent Q-Learning for Partially Observable MDPs
CS 782: Advanced Topics in Machine Learning, Prof. Amit Sethi
Deep Recurrent Q Learning for POMDP
The project presents a unique implementation of an RL-LSTM-Q Network for faster convergence towards optimality while playing Atari 2600 games such as Assault v-5 and Bowling. The innovations implemented include the utilization of domain knowledge for reward function implementation, a rolling window for memory optimization, Cosine Annealing for adapting to escalating difficulty levels, and Transfer Learning using ResNet-18 for image feature extraction, among others.
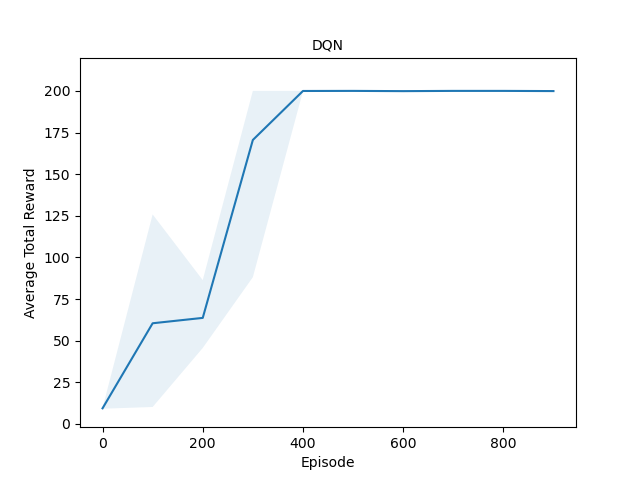
Double Deep Q-Network
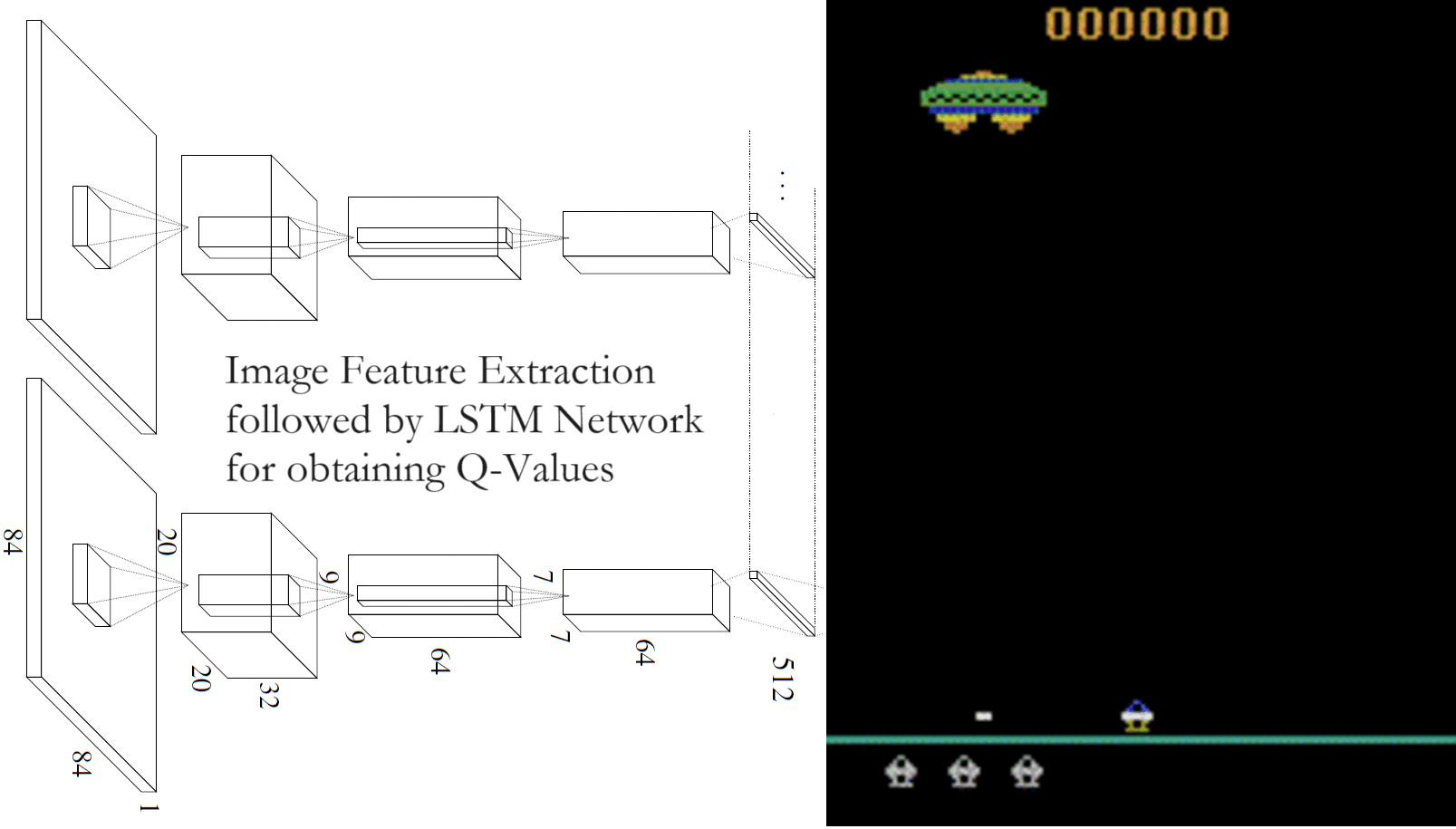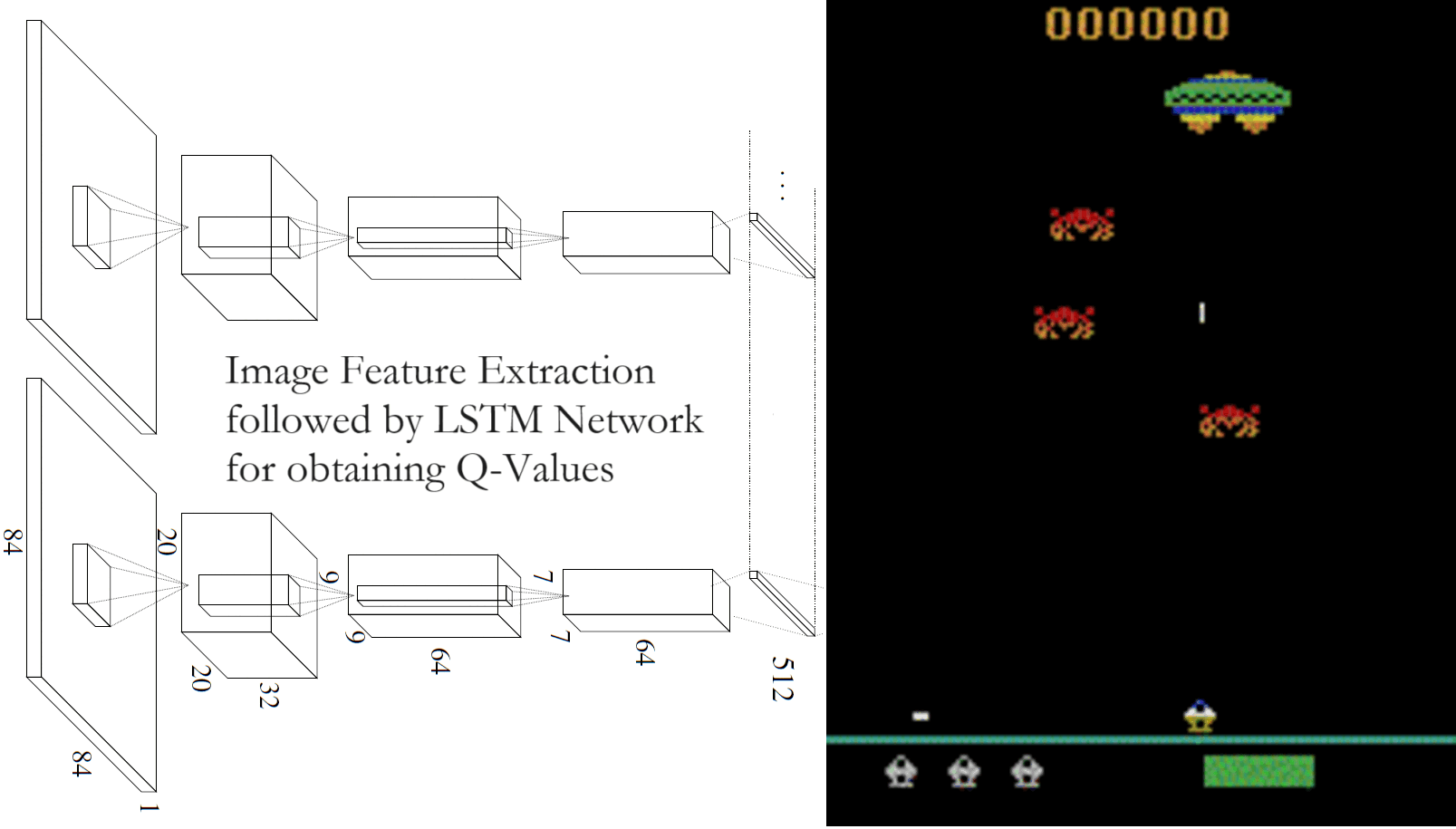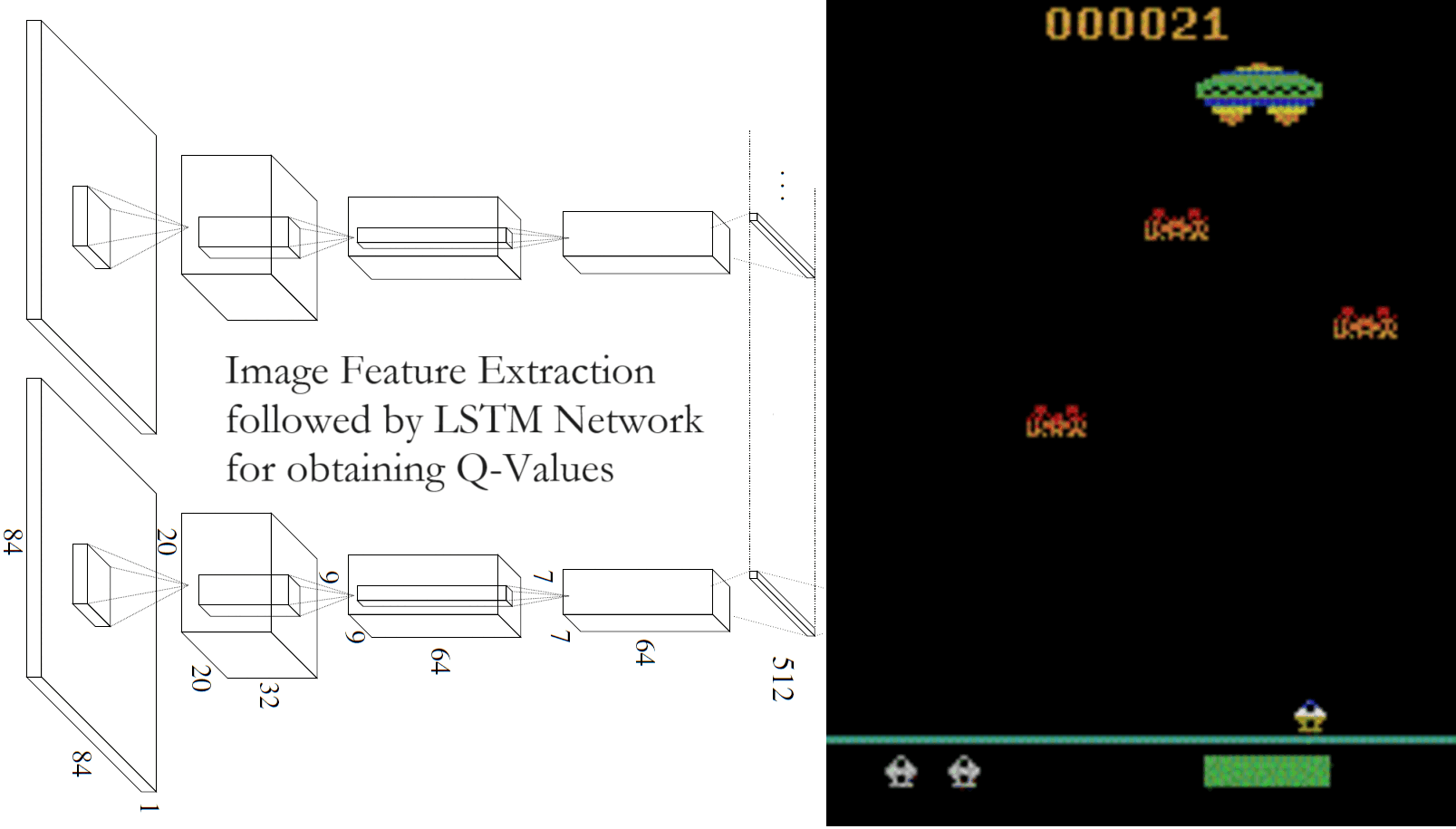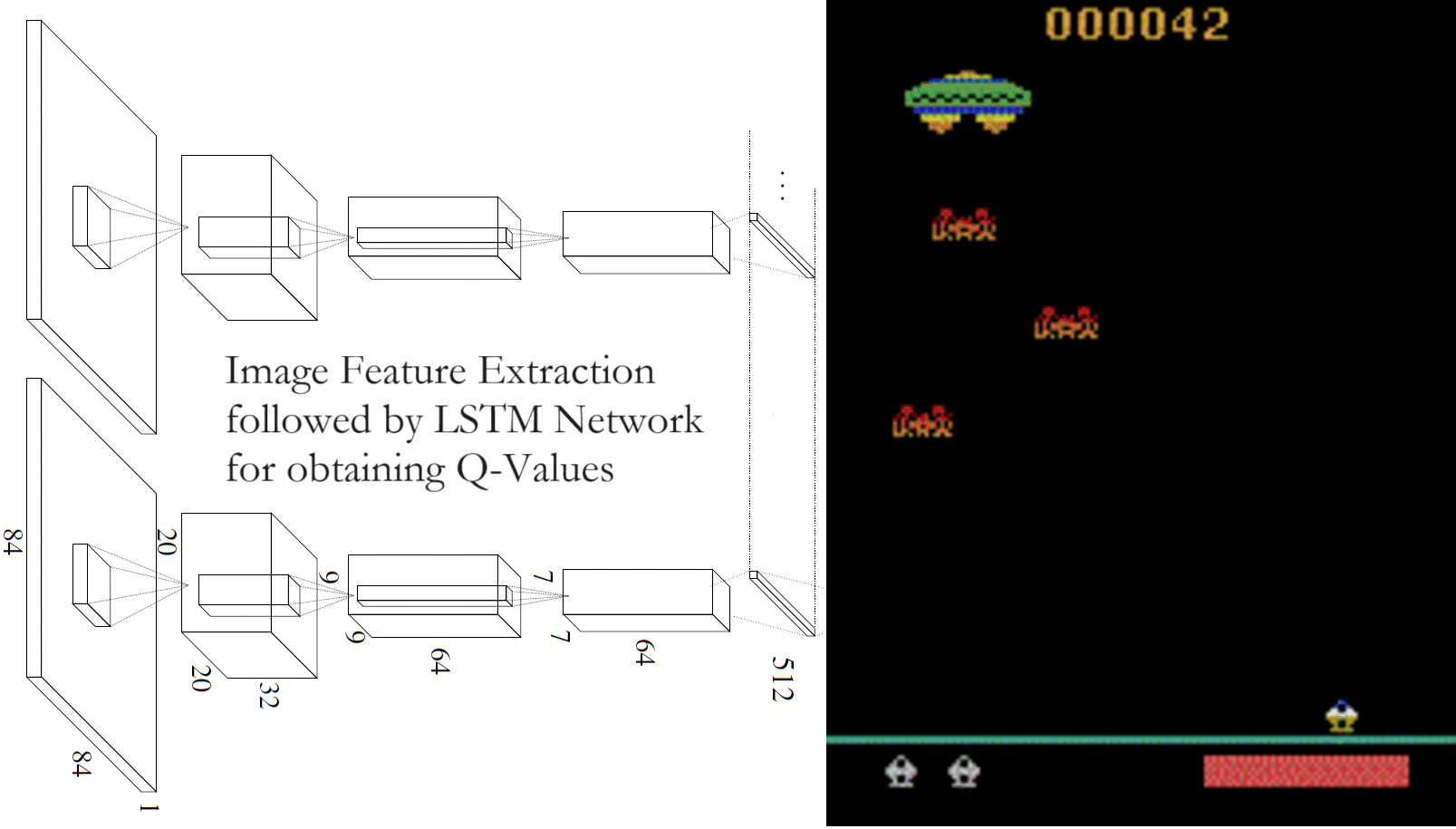
The Architecture Breakdown
1. RL_LSTM_Q_Network
Here we use Transfer-Learning by utilizing a ResNet-18 model as a feature extractor to get the state embedding. We utilize this embedding and pass it on to a Q-network. Q-Learning is a model-free off-policy algorithm for estimating the long-term expected return of executing an action from a given state.
2. Agent, DeepMemory, and EpisodicMemory
The Agent class took center stage, handling memory management, action prediction, and model training. It made use of the DeepMemory and EpisodicMemory classes, offering a structured and efficient approach to handling the extensive data gathered during the learning phase. Bootstrapped Sequential Updates were utilized, and their performance was evaluated on flickering Atari 2600 games.
Rolling Window Optimization for Memory
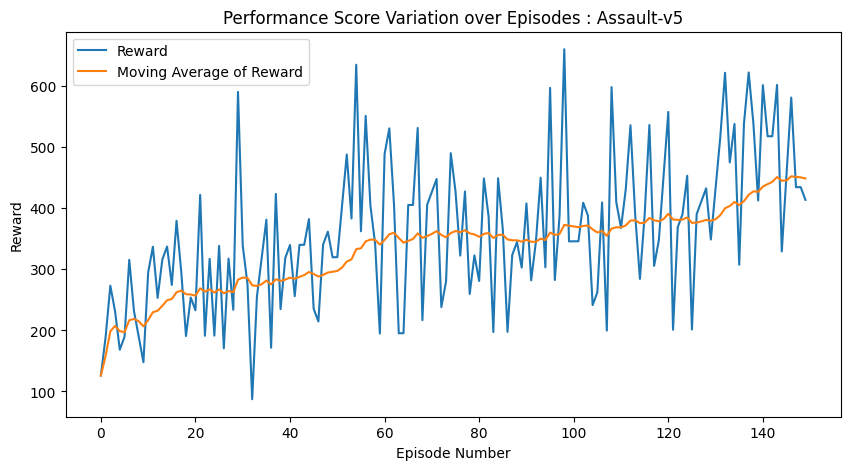
Performance of RL Agent with iterations for Assault-v5
The method employs the Sliding Window Optimization technique, utilizing Long Short-Term Memory (LSTM) operations. By reusing computations from prior timestamp calculations for all frames except the current one (WINDOW SIZE - 1 frames), it achieves a performance boost of x WINDOW SIZE. This approach significantly saves memory by preserving a sequential frame role in deep memory instances rather than storing the entire window for each instance. Dynamically computed during inference, this strategy optimizes computations and efficiently conserves memory resources.
Domain Knowledge for Reward Function Implementation
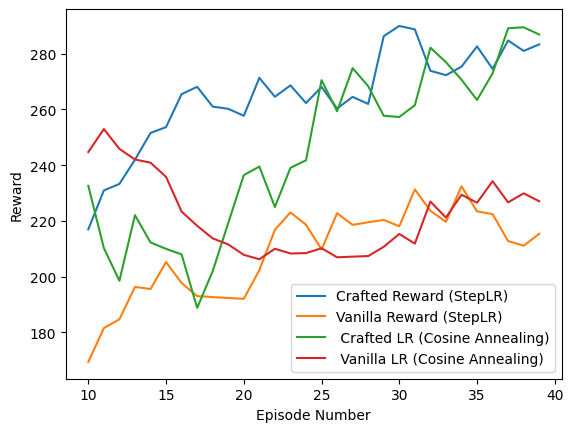
Performance Evaluation of Proposed Approach
Utilizing domain knowledge rooted in general human gameplay, strategies are applied to allocate rewards effectively to the agent. Vanilla Q-Learning loss, assessment of shooting frequency, and consideration of gameplay duration collectively contribute to enhancing the agent’s survivability in the game. This method prevents overheating from continuous firing and prompts selective ‘shooting’ actions as necessary. Training based on these human-inspired strategies aims to elevate the agent’s performance beyond human-level gameplay.