Online Learning
CS 747: Foundations of Intelligent Learning Agents, Prof. Shivaram Kalyanakrishnan
1. Faulty Multi-Arm Bandits

I worked on a bandit instance where pulls are no longer guaranteed to be successful and have a probability of giving faulty outputs sampled from a uniform distribution Unif(0,1). I derived and implemented an asymptotically optimal algorithm to minimize the expected cumulative regret. This algorithm employs Beta distribution sampling, similar to Thompson sampling, while also updating its belief over the arm means based on the probability of a faulty pull.
2. Batched Multi-armed Bandits Problem
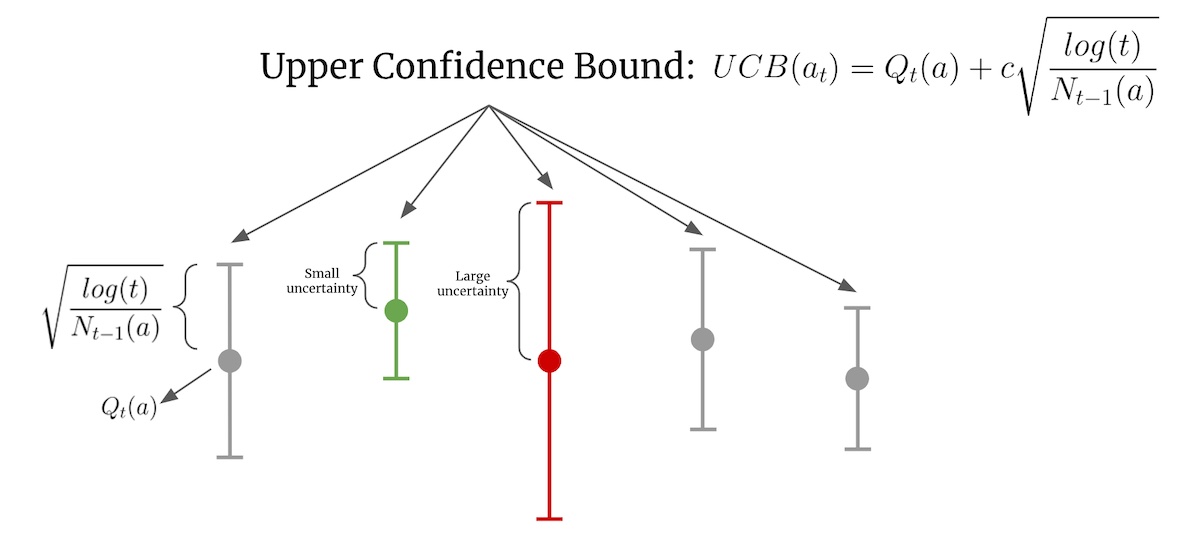
For this task, we had to implement an efficient algorithm for batched sampling, i.e., at every time-step, we were allowed to pull only a fixed number of arms. I devised an asymptotically optimal algorithm that generalizes for arbitrary batch sizes. I approached the problem by implementing a batched sampling variant of Thompson Sampling and KL-UCB that stochastically sampled multiple times from the belief distribution it had of the Bernoulli arms.
Furthermore, I devised an efficient algorithm for multiple bandit instances where the horizon equals the number of arms. The primary aim of the task was to design an algorithm capable of performing significantly better than simply sampling each arm once.